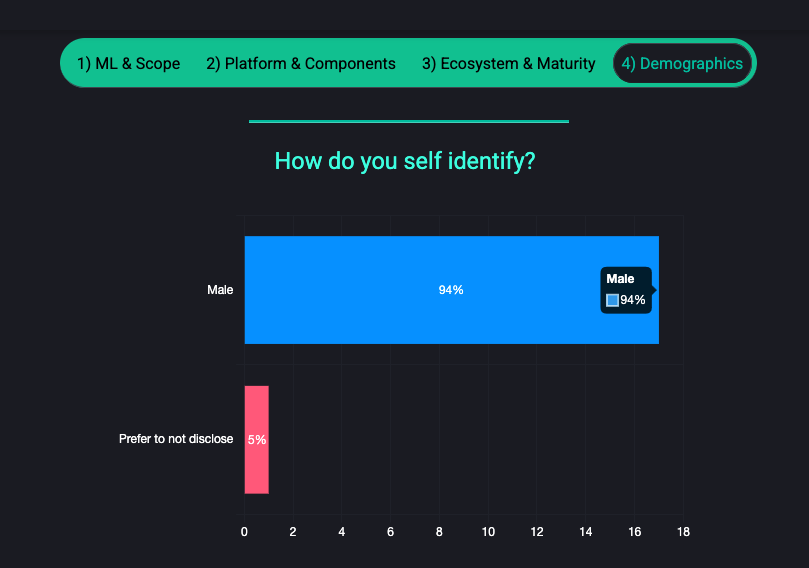
The State of MLOps 2025 Survey 🔥 We've started receiving some responses on the State of Production MLOps in 2025!! However we'll need to do better to collect diverse perspectives to map the ecosystem; help us with your response, as well as by sharing with your colleagues 🚀🚀🚀 If you have a few minutes, your contribution will make a significant difference to the whole production ML ecosystem 🥳 The results will be shared as open source like last year!! You can add your response directly at: https://bit.ly/state-of-ml-2025 🔥 |
|
|
|---|
|
The GPU Compute Compendium Understanding the GPU internals can make a significant difference for ML Engineers looking to get the most out of their compute, and this is a great comprehensive resource on all-things GPU computing: The GPU Glossary is a curated overview of the full GPU stack, covering hardware architecture (e.g., SMs, CUDA/Tensor Cores, schedulers), memory models (threads, blocks, grids, synchronization, global memory), host-side tools (CUDA runtime, drivers, nvcc, profiling suites, cuBLAS), and performance fundamentals (roofline model, occupancy, warp divergence, memory bandwidth limits). Even if you know these concepts this is a really good refresher with great intuitive visuals, definitely worth checking out. |
|
|
|---|
|
OpenAI on LLM Hallucinations Open AI publishes a paper to tackle LLM hallucinations and concludes: 1) accuracy cannot "reach 100%"; 2) hallucinations can be reduced by abstaining; 3) reward metrics may be a key to hallucinations. This is quite an insightful paper where OpenAI explores "Why language models hallucinate", and explains why these "errors" stem not from random glitches but from the statistical limits of next-word prediction. It also seems that this is encouraged through evaluation setups that reward accuracy without penalizing confident mistakes which effectively incentivizing models to guess rather than abstain. There are quite a few interesting lessons which mostly were indirectly (or directly) known, but hammered down, such as reducing hallucinations requires rethinking evaluation, such as by penalizing confidently wrong answers, rewarding abstention or uncertainty, and calibrating outputs. |
|
|
|---|
|
Claude Code Tutorial From Scratch If you haven't yet set up your Claude Code environment, this end-to-end hands-on video series will help you hit the ground running and beyond: This is quite a good, succint, and comprehensive tutorial on claude code which goes all the way from the basics of installation and configuration, to some of the best practices and advanced topics. If you haven't jumped in the Claude Code boat, it basically enables git-aware permission-gated edits, includes code diffs, and supports things like automated PR reviews. This is a good tutorial as it provides some of the intuition on nuances on configuration, assigning narrow / reviewable tasks, manually checking diffs, etc. The content also covers some of the more advanced features such as extensions with MCP servers, custom commands and sub-agents. |
|
|
|---|
|
Google on Limitation of Embedding Retrieval Embeddings are an essential component in AI systems, and understanding their scaling limitations is critical; Google has published an interesting paper that dives into just that: From search to reasoning agents, efficient and accurate retrieval is key and this paper from Google shows that single-vector embedding retrievers face fundamental limits presented as the number of top-k document sets they can represent is bounded by the embedding dimension. Namely what this means is that some simple queries that fall beyond these limitations may be unsolvable regardless of training data or model scale due to this. This paper basically prove this using communication complexity theory and introduce a natural language benchmark where even state-of-the-art dense retrievers achieve under 20% recall on trivial tasks which is quite interesting. It is quite interesting to see research providing similar heuristics to the scaling laws for transformers but covering limitations that would allow ML (Engineering) practitioners to design better AI systems depending on the particular use-cases. |
|
|---|
|
Upcoming MLOps Events The MLOps ecosystem continues to grow at break-neck speeds, making it ever harder for us as practitioners to stay up to date with relevant developments. A fantsatic way to keep on-top of relevant resources is through the great community and events that the MLOps and Production ML ecosystem offers. This is the reason why we have started curating a list of upcoming events in the space, which are outlined below. Upcoming conferences where we're speaking:
Other upcoming MLOps conferences in 2025:
In case you missed our talks:
|
|
|---|
| | |
Check out the fast-growing ecosystem of production ML tools & frameworks at the github repository which has reached over 10,000 ⭐ github stars. We are currently looking for more libraries to add - if you know of any that are not listed, please let us know or feel free to add a PR. Four featured libraries in the GPU acceleration space are outlined below. - Kompute - Blazing fast, lightweight and mobile phone-enabled GPU compute framework optimized for advanced data processing usecases.
- CuPy - An implementation of NumPy-compatible multi-dimensional array on CUDA. CuPy consists of the core multi-dimensional array class, cupy.ndarray, and many functions on it.
- Jax - Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
- CuDF - Built based on the Apache Arrow columnar memory format, cuDF is a GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data.
If you know of any open source and open community events that are not listed do give us a heads up so we can add them! |
|
|---|
| | |
As AI systems become more prevalent in society, we face bigger and tougher societal challenges. We have seen a large number of resources that aim to takle these challenges in the form of AI Guidelines, Principles, Ethics Frameworks, etc, however there are so many resources it is hard to navigate. Because of this we started an Open Source initiative that aims to map the ecosystem to make it simpler to navigate. You can find multiple principles in the repo - some examples include the following: - MLSecOps Top 10 Vulnerabilities - This is an initiative that aims to further the field of machine learning security by identifying the top 10 most common vulnerabiliites in the machine learning lifecycle as well as best practices.
- AI & Machine Learning 8 principles for Responsible ML - The Institute for Ethical AI & Machine Learning has put together 8 principles for responsible machine learning that are to be adopted by individuals and delivery teams designing, building and operating machine learning systems.
- An Evaluation of Guidelines - The Ethics of Ethics; A research paper that analyses multiple Ethics principles.
- ACM's Code of Ethics and Professional Conduct - This is the code of ethics that has been put together in 1992 by the Association for Computer Machinery and updated in 2018.
If you know of any guidelines that are not in the "Awesome AI Guidelines" list, please do give us a heads up or feel free to add a pull request!
|
|
|---|
| | |
| | | | The Institute for Ethical AI & Machine Learning is a European research centre that carries out world-class research into responsible machine learning. | | | | |
|
|
|---|
|
|
This email was sent to You received this email because you are registered with The Institute for Ethical AI & Machine Learning's newsletter "The Machine Learning Engineer"
|
| | | | |
|
|
|---|
|
© 2023 The Institute for Ethical AI & Machine Learning |
|
|---|
|
|
|