The results for the Survey on Production MLOps are out: ethical.institute/state-of-ml-2025 🚀🚀🚀 As part of the release we have updated the interface enabling real time toggling between 2024 and 2025 data, and have refreshed a cool new code-editor theme 😎 Check it out and share it around!! |
| 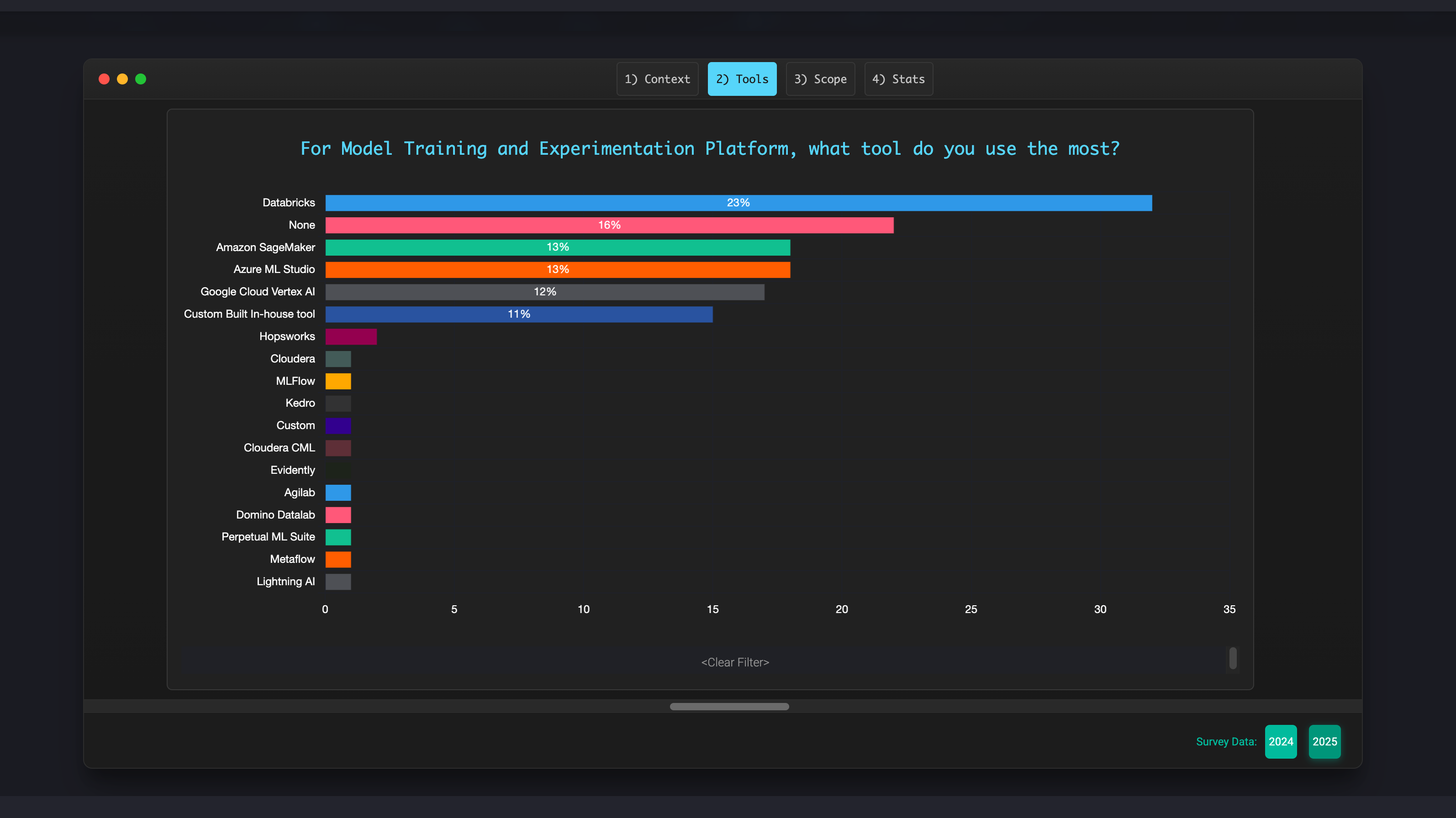 | Some insights: In 2025, about 23% of organisations are training using Databricks to train their ML models (vs 18% in 2024), followed by 13% using AWS Sagemaker (vs 14% in 2024), closely followed by a tie of 12% for both Google Vertex AI (vs 8% in 2024) and Azure ML Studio (vs 6% in 2024). It is interesting to see that there's both a continued trend towards DBX; similarly there is an opposite trend on organisations building their custom in-house training platforms down to 11% in 2025 vs 28% in 2024. The space of model training platforms seems to have become the most consolidated domain across the entire end-to-end ML lifecycle as part of the survey, which aligns with my anecdotal experience. You can access the full results here: https://ethical.institute/state-of-ml-2025 |
| | |
|
|
|---|
|
Raschka on DeepSeek v3.2
Sebastian Raschka has put together the best breakdown of DeepSeek's recent V3.2 model release, and there are some pretty interesting architectural choices that make it clear why it's so far ahead: This release was quite exciting as it's starting to feel like one of those moments where open-weight models are now a serious replacement for frontier closed-source models in real production stacks, and we are also hearing news like OpenAI declaring code red due to lack of moat. I really liked how Sebastian Raschka introduced the architecture choices by actually going through breakthroughs in previous models that actually have now enabled by bringing these all together. The most interesting one was the concept of sparse attention, which he explains how it's different to windowed / sequential attention in that it allows the model to focus on sparse historical tokens instead of being restricted to say the last n tokens. Similarly there are some interesting breakthroughs on the Mixture-of-Experts backbone built on a Multi-Head Latent Attention trick for cheap KV caching, and pushing hard on the RL side mixing classic RLVR for math/code with LLM-as-a-judge rewards and domain-specific GRPO tweaks. Reading through this really shows how this release has been truly achieved by a small series of breakthroughs from previous iterations, and does make it clear that releasing fast really can give the competitive advantage (which many of the larger players are missing - although not google surprisingly!) |
|
|
|---|
|
DeepMind Nobel Prize Documentary The recent DeepMind documentary is actually a must-watch! I remember the good old days working in AI back in the mid 2010s, watching how AlphaGo blew minds with move 37... back then there wasn't much hype for the field - funnily enough, the hype was all about crypto 😂 This documentary seems to really capture the excitement on how the hype delivered into one absolutely exciting breakthrough from DeepMind on protein folding, which so far has not yet been processed widely across the mainstream. There are quite a lot of really nostalgic, and particularly exciting details that are covered in the documentary that I wasn't aware of; definitely recommend the watch! Back in these days is when I started working on Responsible AI given how critical it was becoming, I am very much glad I did as although there's been progress, there is still quite a lot to do (and arguably more with the accelerated pace of innovation in the field!). |
|
|
|---|
|
The State of MLOps 2025 Survey 🔥 In 2025, about 23% of organisations are training using Databricks to train their ML models (vs 18% in 2024), followed by 13% using AWS Sagemaker (vs 14% in 2024), closely followed by a tie of 12% for both Google Vertex AI (vs 8% in 2024) and Azure ML Studio (vs 6% in 2024). It is interesting to see in our 2025 survey on the State of Production ML that there's both a continued trend towards DBX; similarly there is an opposite trend on organisations building their custom in-house training platforms down to 11% in 2025 vs 28% in 2024. The space of model training platforms seems to have become the most consolidated domain across the entire end-to-end ML lifecycle as part of the survey, which aligns with my anecdotal experience. 🥳 The results are shared as open source like last year! You can access them directly at: https://ethical.institute/state-of-ml-2025 🔥 |
|
|
|---|
|
The Race of DuckDB / Polars / Spark In production ML we're all feeling the pain of "cluster fatigue" - I am glad we are not taking the run-in-my-laptop challenge to the next level with benchmarks of tools like DuckDB / Polars / Spark which are very promising: This is a great experiment - namely asking, can I just process a 650GB S3 bucket on a simple 32GB / 16-CPU machine? The answer is (as always) "it depends - but likely yes" with the right tools, which is great to see. This use-case shows how DuckDB, Polars, and Daft can happily chew through a full-table aggregation without blowing up within ~12–16 minutes for Polars/DuckDB and ~50 minutes for Daft. The PySpark job (untuned) was also able to chew through it in a bit over an hour, but certainly there can be further optimizations that can be introduced. I myself have been playing around with DuckDB in various random projects and I have to say I'm impressed on the performance, and seeing also the integrations that it's providing into data lakes makes it increasible more feasible, definitely recommend checking it out! |
|
|
|---|
|
Advent of SadServers 2025 In production ML, the real outages usually come not from your models but from the Linux, Docker, and web infrastructure holding them up - this Christmas we can dive into the Advent of DevOps: This is a great initiative similar to the traditional Advent of Code, but focusing on DevOps channels, and although it's not directly and MLOps set of challenges, from experience most of the challenges in production ML systems infra will require these type of drills to address. Some of these challenges are things like debugging an nginx reverse proxy in Docker, restoring a broken stack so the frontend can talk to its backend, fixing file permissions so a normal user can reliably create and edit files across sessions, etc. What better way to spend your Christmas than feeling like you're debugging in production! |
|
|
|---|
|
Upcoming MLOps Events The MLOps ecosystem continues to grow at break-neck speeds, making it ever harder for us as practitioners to stay up to date with relevant developments. A fantsatic way to keep on-top of relevant resources is through the great community and events that the MLOps and Production ML ecosystem offers. This is the reason why we have started curating a list of upcoming events in the space, which are outlined below. Upcoming conferences where we're speaking:
Other upcoming MLOps conferences in 2025:
In case you missed our talks:
|
|
|---|
| | |
Check out the fast-growing ecosystem of production ML tools & frameworks at the github repository which has reached over 10,000 ⭐ github stars. We are currently looking for more libraries to add - if you know of any that are not listed, please let us know or feel free to add a PR. Four featured libraries in the GPU acceleration space are outlined below. - Kompute - Blazing fast, lightweight and mobile phone-enabled GPU compute framework optimized for advanced data processing usecases.
- CuPy - An implementation of NumPy-compatible multi-dimensional array on CUDA. CuPy consists of the core multi-dimensional array class, cupy.ndarray, and many functions on it.
- Jax - Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
- CuDF - Built based on the Apache Arrow columnar memory format, cuDF is a GPU DataFrame library for loading, joining, aggregating, filtering, and otherwise manipulating data.
If you know of any open source and open community events that are not listed do give us a heads up so we can add them! |
|
|---|
| | |
As AI systems become more prevalent in society, we face bigger and tougher societal challenges. We have seen a large number of resources that aim to takle these challenges in the form of AI Guidelines, Principles, Ethics Frameworks, etc, however there are so many resources it is hard to navigate. Because of this we started an Open Source initiative that aims to map the ecosystem to make it simpler to navigate. You can find multiple principles in the repo - some examples include the following: - MLSecOps Top 10 Vulnerabilities - This is an initiative that aims to further the field of machine learning security by identifying the top 10 most common vulnerabiliites in the machine learning lifecycle as well as best practices.
- AI & Machine Learning 8 principles for Responsible ML - The Institute for Ethical AI & Machine Learning has put together 8 principles for responsible machine learning that are to be adopted by individuals and delivery teams designing, building and operating machine learning systems.
- An Evaluation of Guidelines - The Ethics of Ethics; A research paper that analyses multiple Ethics principles.
- ACM's Code of Ethics and Professional Conduct - This is the code of ethics that has been put together in 1992 by the Association for Computer Machinery and updated in 2018.
If you know of any guidelines that are not in the "Awesome AI Guidelines" list, please do give us a heads up or feel free to add a pull request!
|
|
|---|
| | |
| | | | The Institute for Ethical AI & Machine Learning is a European research centre that carries out world-class research into responsible machine learning. | | | | |
|
|
|---|
|
|
This email was sent to You received this email because you are registered with The Institute for Ethical AI & Machine Learning's newsletter "The Machine Learning Engineer"
|
| | | | |
|
|
|---|
|
© 2023 The Institute for Ethical AI & Machine Learning |
|
|---|
|
|
|