| | 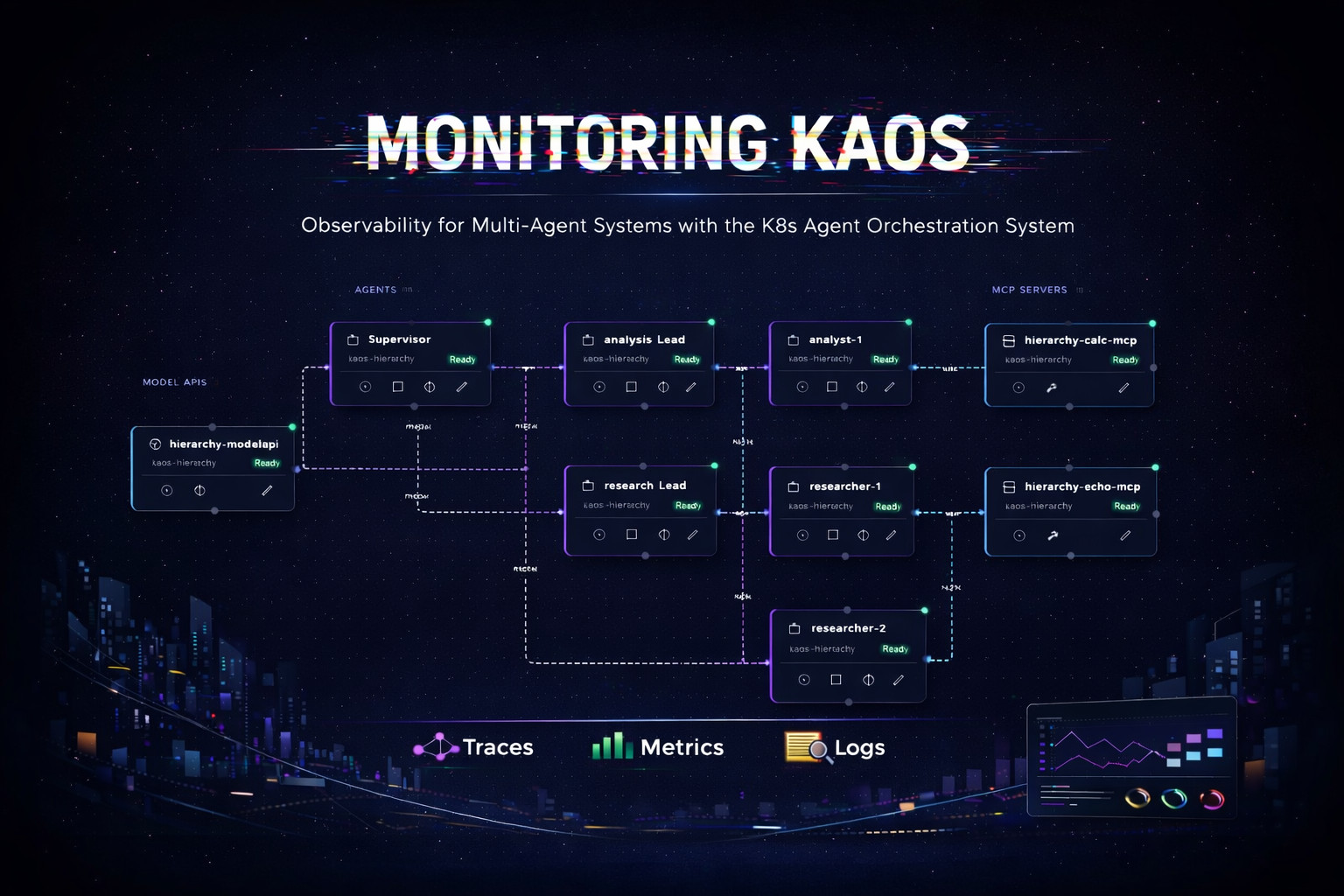 | Sharing a new blog post on "Monitoring KAOS: Observability for Multi-Agent Systems with OpenTelemetry" 🚀 This is a thorough deep dive that explores how to instrument distributed agent loops that span across multiple Agents, MCP Servers and Model APIs.
The main premise is basically that multi-agent systems work - that is, until they don't. Your prod user complains: "it took forever" / "it gave a strange response" / "it worked yesterday"; and your request/response show no errors...
In agentic systems monitoring is more complex, as request flows involve complex hops - eg:
HTTP POST /v1/chat/completions
coordinator.agent.agentic_loop (trace_id: abc123)
----> coordinator.model.inference
----> coordinator.delegate.researcher
---- ----> researcher.agent.agentic_loop (trace_id: abc123)
---- ----> researcher.model.inference
---- ---- -----> researcher.tool.web_search
---- ----> coordinator.model.inference
----> coordinator.delegate.analyst
----> analyst.agent.agentic_loop (trace_id: abc123)
---- ----> analyst.model.inference
---- ----> analyst.tool.calculator
...and requests can last anywhere from 100ms to 60+ seconds depending on what the agent decides to do.
In this post we dive into how we can distributed agent loops observable using:
Traces: "what path did the request take through agents/tools/models?"
Logs: "what did the agent think / decide at each step?"
Metrics: "is this getting worse over time?"
We take a complex multi-agent use-case consisting of an Agent Supervisor with multiple Researcher + Analyst sub-agents, and walk through each of these components showing how to perform root-cause-analysis using the right tools and techniques. Check it out! |
|
|
|---|
|
CircleCI 2026 Delivery Report The 2026 State of Software Delivery makes it clear that GenAI is starting to show major productivity gains, but these are (VERY) unevenly distributed: CircleCI analyses 28.7M+ CI workflows to understand the main trends on software delivery, which include AI adoption, blockers, tooling and more. The main thing that really jumps out is that there is a really large widening the gap between teams who can reliably ship and those who can't. Average CI throughput via daily workflows rose 59% YoY, however these gains are heavily concentrated among the top 5% performers, which basically doubled throughput, whilst the median and bottom-quartile teams saw very little improvement. The most interesting insight is that integration/validation can’t keep up with the development throughput speed. Most teams see more activity on feature branches (+15%) but main-branch throughput is actually decreasing (−6.8%) which means more code gets written than successfully promoted to production. Reliability metrics seem are also worsening, with main-branch success rate dropping to ~70.8%, with median TTR rising to ~72 minutes, meaning that AI-generated complexity is resulting in more frequent breakages and longer debugging cycles. The pattern that is clearly "winning" is teams that are able to scale validation and recovery with volume. This is the time to figure out how to enable the accelerated speed; this is one of the key points that I raised as part of my keynote at WeAreDevelopers last year, namely calling out the gap in GenAI maturity at the lower developer funnel (starting at 6:23). |
|
|
|---|
|
| | 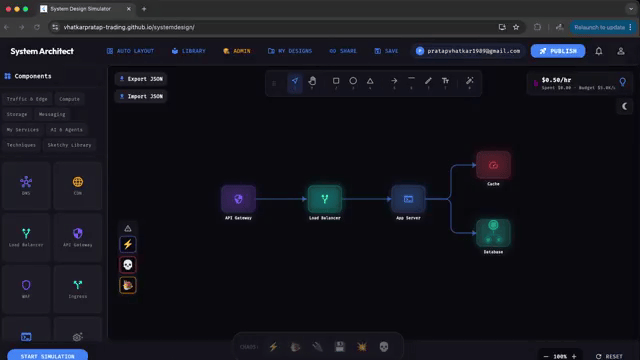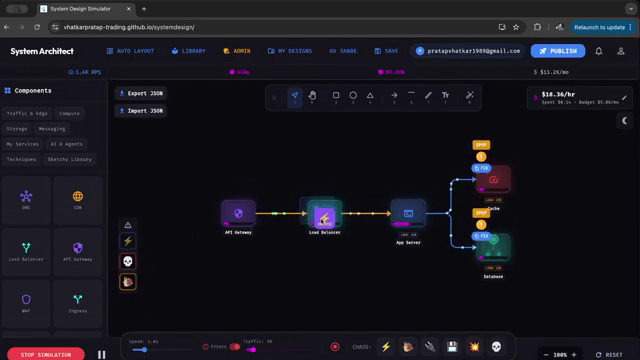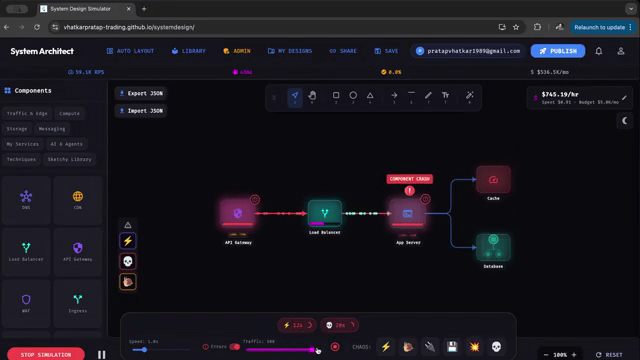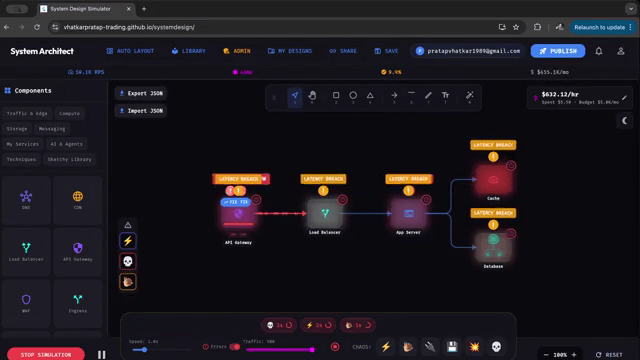 | This is an absolutely brilliant (sims-like?) application that allows you to set-up a system and simulate how it would perform at certain traffic/scalability levels. It's basically a lightweight System Design Simulator that turns architecture diagrams into an interactive playable model which you can drag-and-drop. It has quite a pretty broad set of components, it includes LBs, API gateways, caches, DBs, queues (even AI blocks), and you can then basically see how your system thrives or crumbles in real time. It even has some "chaos toggles" like traffic spikes, cache-miss storms, partitions, crashes so you can quickly explore failure modes and trade-offs without provisioning infra. I have to say this is pretty awesome, I would love for future educational resources to leverage some of these type of approaches, it's been really interesting to see the type of things that people are inventing these days. It basically feels like a race of creativity and innovation, it's great! |
|
|
|---|
|
Karpathy's 200-line MicroGPT Andrej Karpathy is at it again with now a (micro) 200-line implementation of the GPT model behind ChatGPT/Claude/etc; as always with a really intuitive and easy to understand walkthrough: This MicroGPT implementation really is the "minimum viable GPT" as it's the smallest / simplest implementation I've seen with only ~200-250 lines of dependency-free Python. It basically contains the full flow including data loading, a tiny character-level tokenizer (plus BOS), a scalar autograd engine, a GPT-2-like Transformer (embeddings, RMSNorm, multi-head causal self-attention with an explicit KV cache, MLP, residuals), Adam, a training loop with cross-entropy, and an autoregressive sampling loop with temperature. It is pretty crazy to see how Andrej Karpathy is able to continue to provide some of the best educational resources on the topic whilst being able to stay on top of all the innovation going around. |
|
|
|---|
|
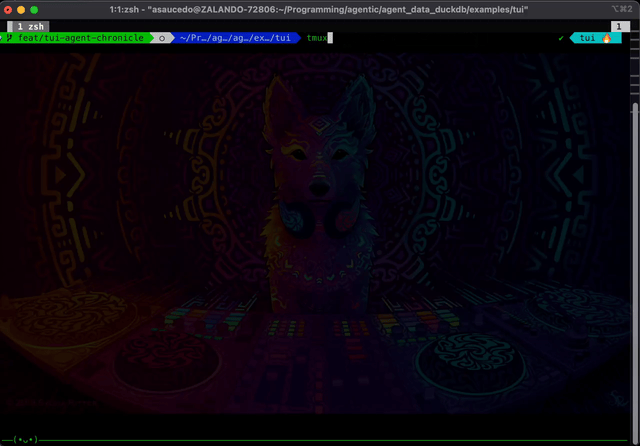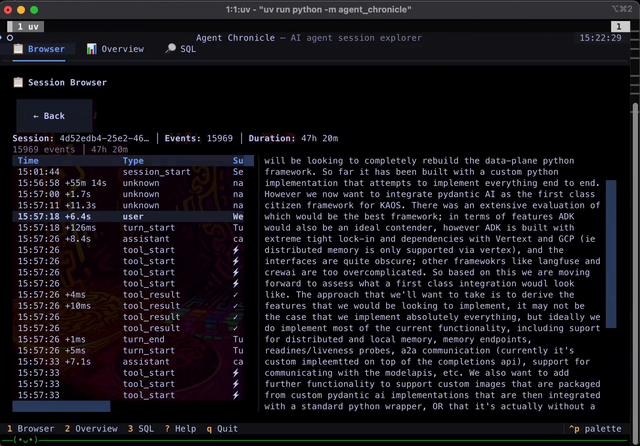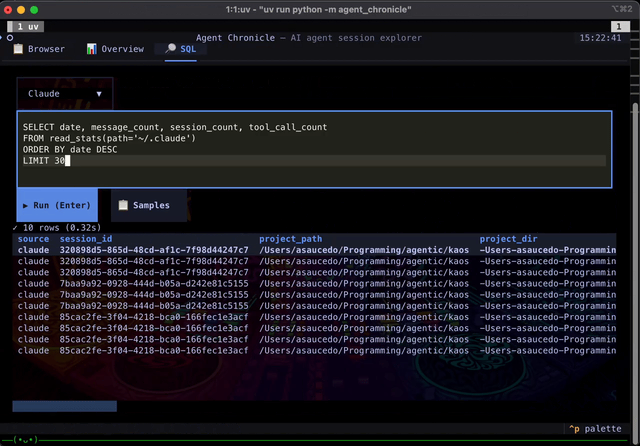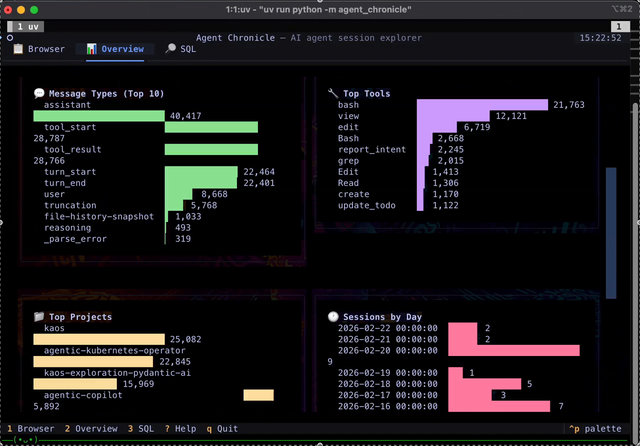
| | 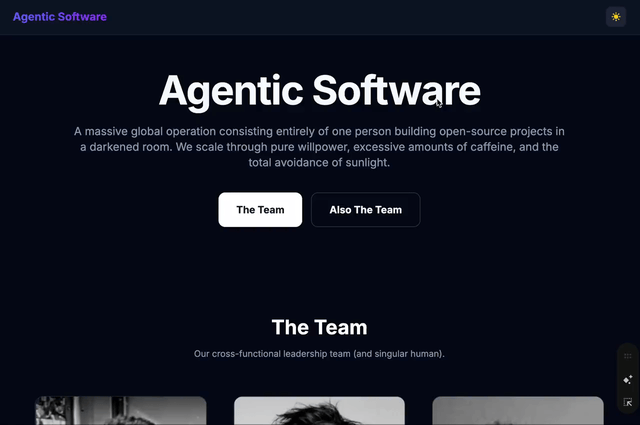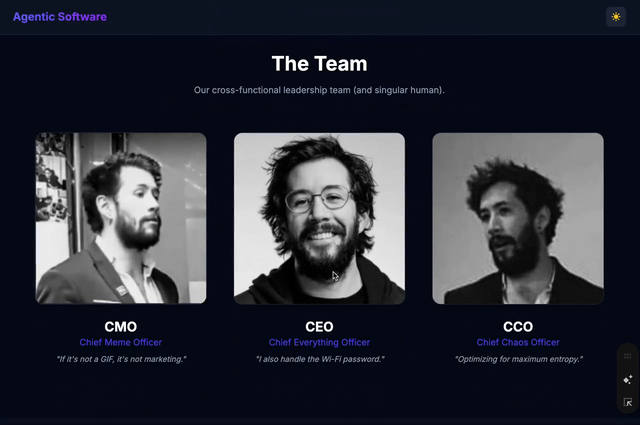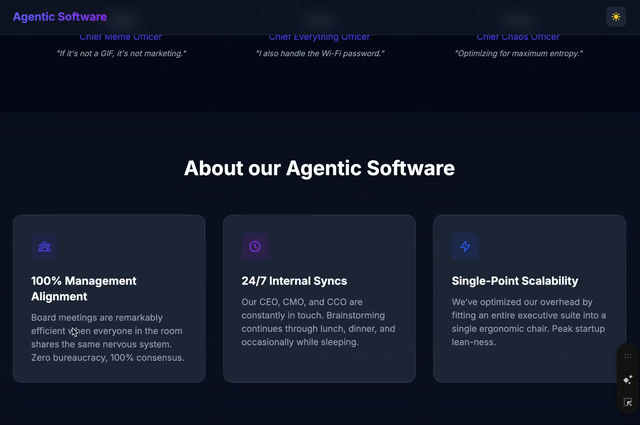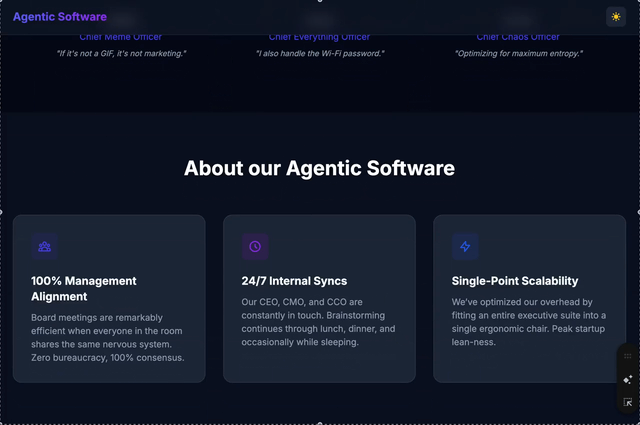 | On the topic of side-projects: This weekend I asked copilot to build me a joke website about agentic software for the newsletter. Within a few minutes it found three pictures of me, created a website, and it's actually pretty funny! It configured the github pages, made it mobile friendly, added dark/light theme - I am impressed, check it out! Seems like now even it's so cheap you can even make websites instead of memes... And this is not even what was planned to share as the main OSS project this week; as shown in the intro, the main exciting launch is the development of a TUI for the DuckDB Extension to query your Claude/Copilot; check this one out as well! |
|
|
|---|
|
Upcoming MLOps Events The MLOps ecosystem continues to grow at break-neck speeds, making it ever harder for us as practitioners to stay up to date with relevant developments. A fantsatic way to keep on-top of relevant resources is through the great community and events that the MLOps and Production ML ecosystem offers. This is the reason why we have started curating a list of upcoming events in the space, which are outlined below.
Events we are speaking at this year:
Other relevant events:
In case you missed our talks, check our recordings below:
|
|
|---|
| | |
Check out the fast-growing ecosystem of production ML tools & frameworks at the github repository which has reached over 20,000 ⭐ github stars. We are currently looking for more libraries to add - if you know of any that are not listed, please let us know or feel free to add a PR. Here's a few featured open source libraries that we maintain: - KAOS - K8s Agent Orchestration Service for managing the KAOS in large-scale distributed agentic systems.
- Kompute - Blazing fast, lightweight and mobile phone-enabled GPU compute framework optimized for advanced data processing usecases.
- Production ML Tools - A curated list of tools to deploy, monitor and optimize machine learning systems at scale.
- AI Policy List - A mature list that maps the ecosystem of artificial intelligence guidelines, principles, codes of ethics, standards, regulation and beyond.
- Agentic Systems Tools - A new list that aims to map the emerging ecosystem of agentic systems with tools and frameworks for scaling this domain
Please do support some of our open source projects by sharing, contributing or adding a star ⭐ |
|
|---|
| | |
| | | | The Institute for Ethical AI & Machine Learning is a European research centre that carries out world-class research into responsible machine learning. | | | | |
|
|
|---|
|
|
This email was sent to You received this email because you are registered with The Institute for Ethical AI & Machine Learning's newsletter "The Machine Learning Engineer"
|
| | | | |
|
|
|---|
|
© 2023 The Institute for Ethical AI & Machine Learning |
|
|---|
|
|
|